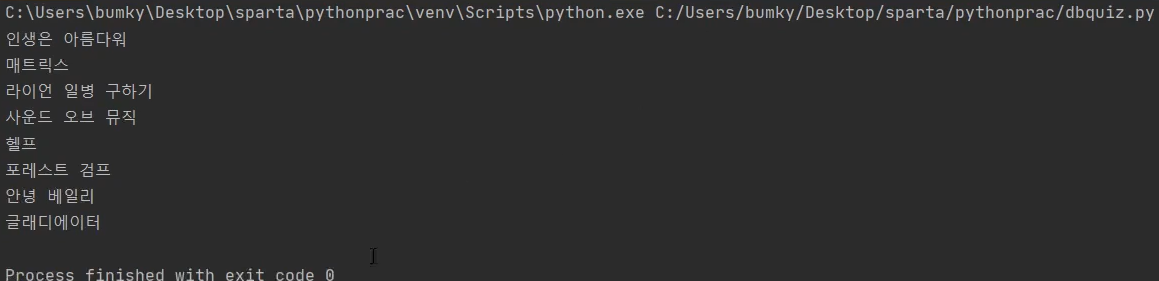
DB Quiz 1 '매트릭스'의 평점 가져오기
from pymongo import MongoClient
client = MongoClient ( 'localhost' , 27017 )
db = client .dbsparta
movie = db .movies. find_one ({ 'title' : '매트릭스' })
target_star = movie [ 'star' ]
완성 된 결과물
DB Quiz 2 '매트릭스'의 평점과 같은 평점의 영화 제목들을 가져오기
from pymongo import MongoClient
client = MongoClient ( 'localhost' , 27017 )
db = client .dbsparta
movie = db .movies. find_one ({ 'title' : '매트릭스' })
target_star = movie [ 'star' ]
target_movies = list ( db .movies. find ({ 'star' : target_star },{ '_id' : False }))
#리스트에 딕셔너리가 들어있는 경우는 for문 사용
for target in target_movies :
print ( target [ 'title' ])
완성 된 결과물
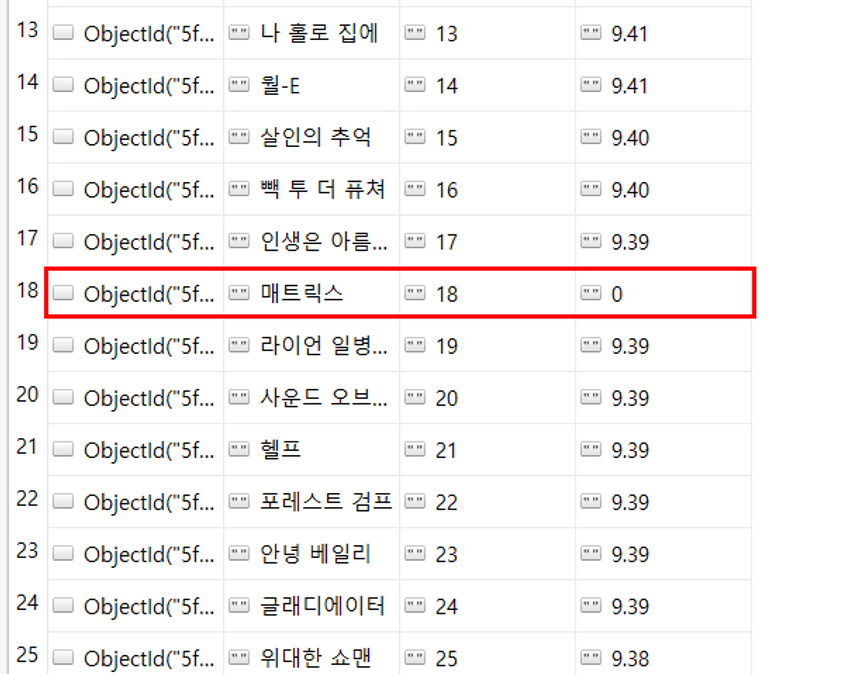
DB Quiz 3 매트릭스 영화의 평점을 0으로 만들기
db .users. update_one ({ 'name' : 'bobby' },{ '$set' :{ 'age' : 19 }}) # 업데이트 문에서 가져와 아래처럼 변형해 쓴다
from pymongo import MongoClient
client = MongoClient ( 'localhost' , 27017 )
db = client .dbsparta
db .movies. update_one ({ 'title' : '매트릭스' },{ '$set' :{ 'star' : 0 }})
이렇게 되면 완성
프로젝트 연습 - 지니뮤직 사이트에서 1-50위 곡 크롤링 해보기
먼저 hellp.py 에서 했던 부분을 그대로 가져온 후 아래 지니뮤직 url 링크로 바꿔준다
https://www.genie.co.kr/chart/top200?ditc=D&rtm=N&ymd=20230606
지니차트>일간 - 지니
AI기반 감성 음악 추천
www.genie.co.kr
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient ( 'localhost' , 27017 )
db = client .dbsparta
# URL을 읽어서 HTML를 받아오고,
headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36' } #아래 ↓ 링크를 지니뮤직 링크로 바꿔주기
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
soup = BeautifulSoup ( data . text , 'html.parser' )
# 위 코드들을 print(soup)로 프린트해서 html 코드들이 잘 찍히는지 확인 먼저 해보기
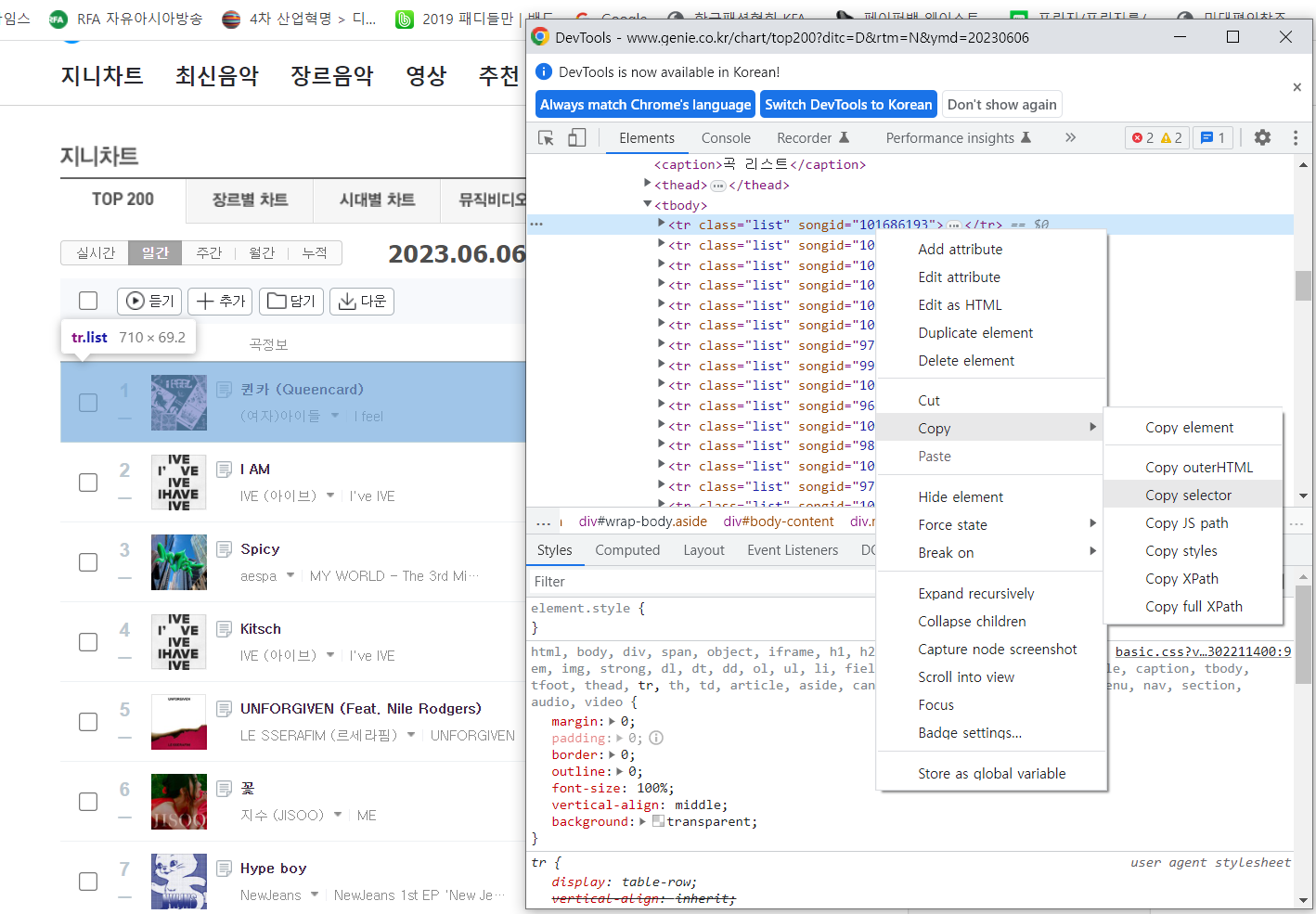
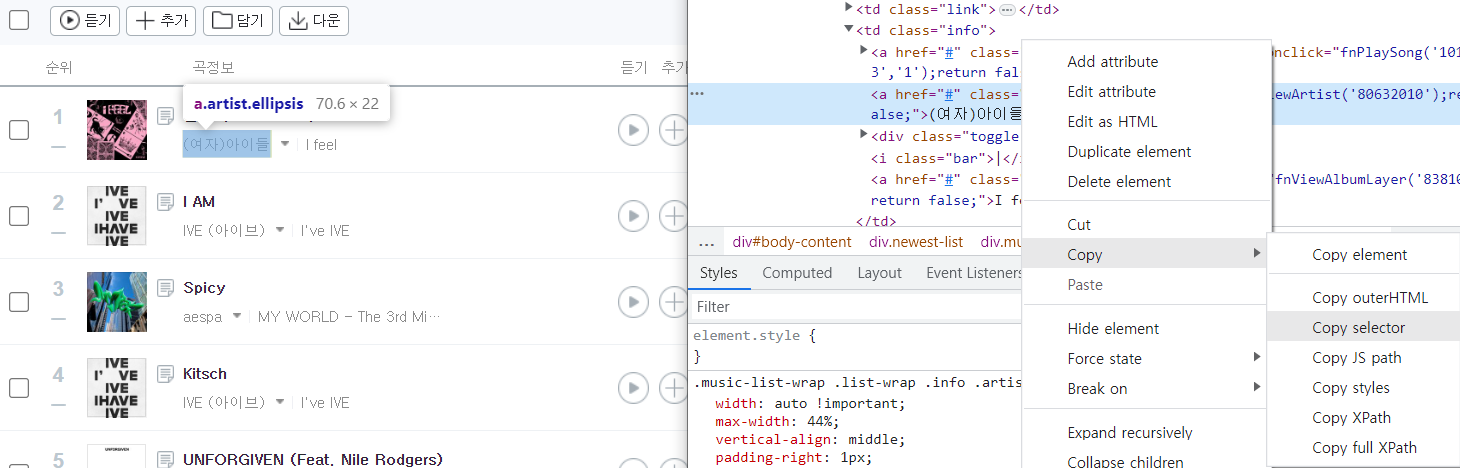
지니 뮤직 사이트에서 검사를 통해 개발자 도구창을 열고 순위, 제목, 가수를 가져오기
먼저 ' tr ' 을 vscode 로 먼저 가져가본다
copy → copy selector
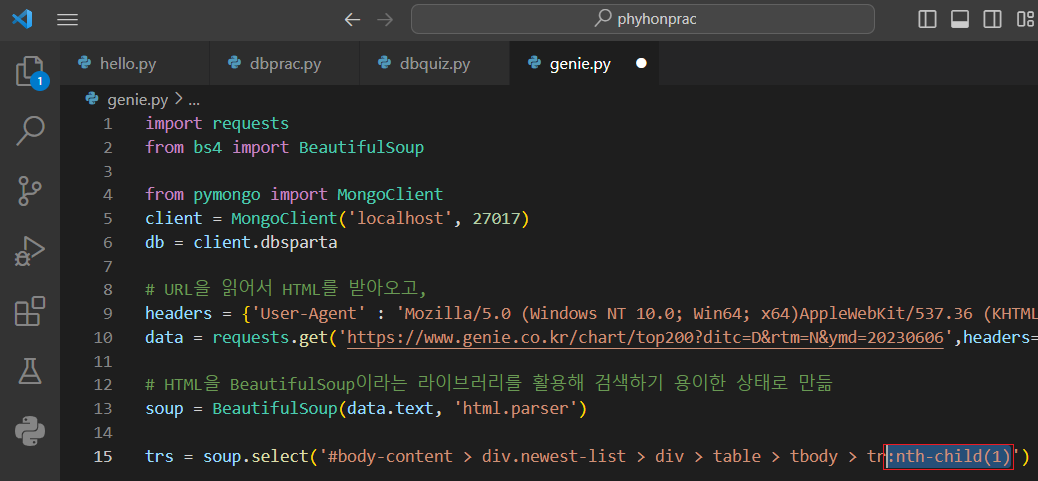
tr들을 그대로 가져오려면 ' tr:nth-child(1) ' 부분에서 nth-child(1)만 삭제해야함을 발견할 수 있다
#body-content > div.newest-list > div > table > tbody > tr:nth-child (1)
:nth-child(1) 부분 삭제
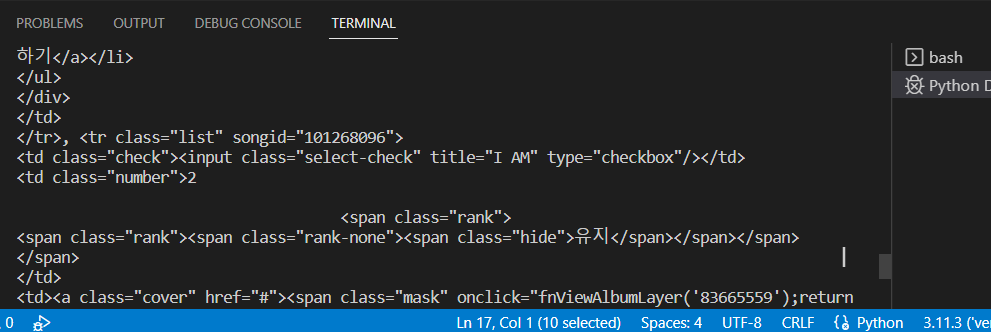
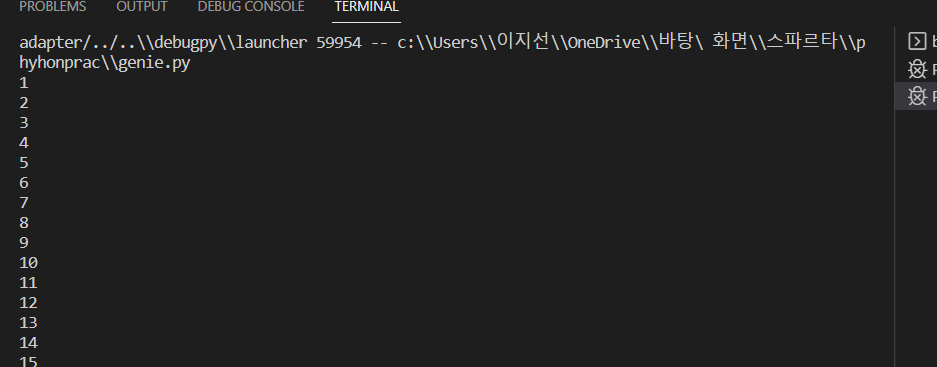
이 때, print(trs)를 입력하고 c+f5 실행을 하면 tr들이 터미널 cmd 창에 리스트 형식으로 뜨는 것을 확인 할 수 있다.
for 반복문을 사용해서 개발자 도구에서 가져온 코드를 입력해보기
복사한 tr 코드: #body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.title.ellipsis
'#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) >' # 삭제할 부분
'td.info > a.title.ellipsis' #사용할 부분
위 코드에서 tr 까지는 soup.select () 안에 들어간 코드랑 똑같기 때문에 지워주고 td.info > a.title.ellipsis 이 부분만 사용
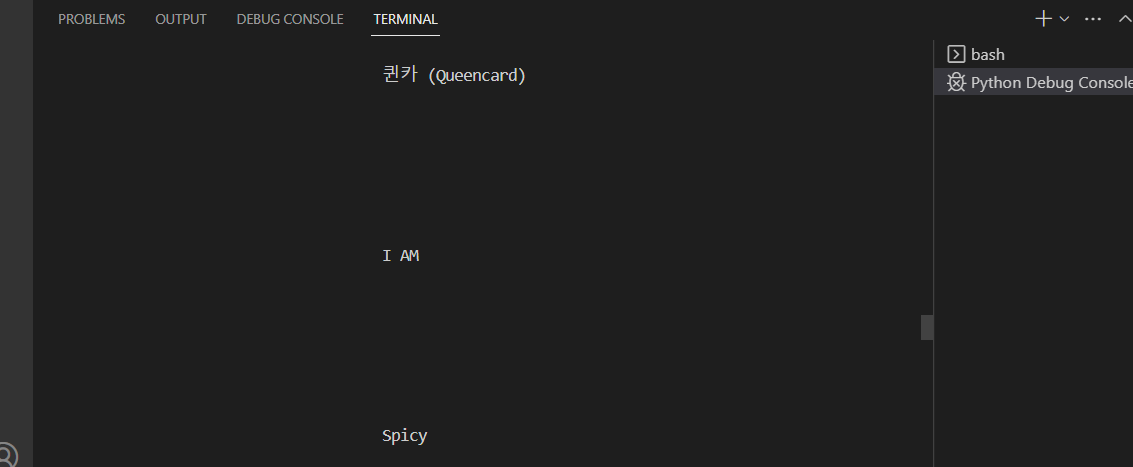
이제 print(title.text) 이 코드를 실행시켜서 제목만 가져와보면 터미널에 공백이 있는채로 제목들이 뜬다.
이 공백들을 없애주기 위해 '파이썬 공백 제거' 구글링을 해보면 파이썬 내장 함수인 .strip ( ) 을 사용하라고 나온다.
print ( title . text . strip ())
print(title) 뒤에 붙여주던 .text.strip( ) 을 위에 있는 title 에 옮겨 붙여도 title 이 똑같기 때문에 무방하다.
title = tr . select_one ( 'td.info > a.title.ellipsis' ). text . strip ()
ㄴ위와 같이 프린트 해주면 공백이 제거 된 채로 제목들이 나열되는 것을 볼 수 있다.
이제 print(title) 부분은 삭제하고 순위(rank) 코드를 짜보러 가보자
마찬가지로 개발자 도구에서 순위 td 를 찾아주고 copy selector 를 통해 복사한다.
#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.number
tr 까지는 똑같으므로 #body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > 부분은 삭제한다.
그러면 아래와 같은 코드처럼 입력할 수 있다.
rank - tr . select_one ( 'td.number' )
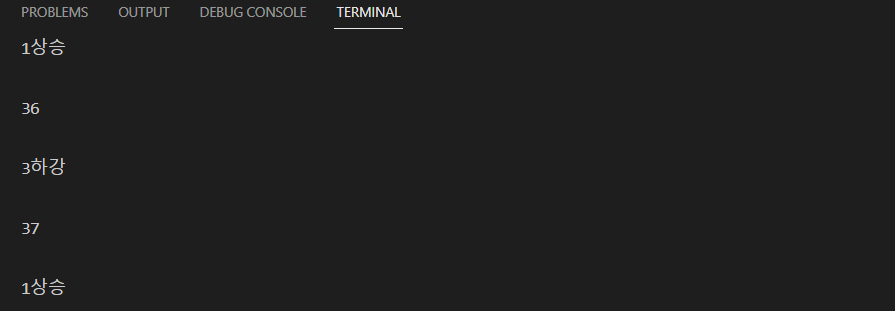
자, 이쯤에서 print(rank.text) 로 중간 점검을 해주자
파이썬 문자열 자르기를 통해 숫자 부분만 가져와야 함을 발견할 수 있다.
print ( rank . text [ 0 : 2 ]. strip ())
1-50 순위까지 있는 페이지므로 두자릿수임을 표현하는 [0:2] 사용, 그 뒤 .strip( ) 까지 동원하면 위와 같은 순위들이 나열된다.
for tr in trs :
title = tr . select_one ( 'td.info > a.title.ellipsis' ). text . strip ()
rank = tr . select_one ( 'td.number' ). text [ 0 : 2 ]. strip ()
print ( rank )
마찬가지로 .text[0:2].strip( ) 이 코드는 print 바로 위 rank = tr.select_one('td.number') 옆에다 붙여줘도 된다.
마지막으로 가수 이름을 가져오기 위해 copy selector 를 통해 코드를 짜보자.
#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.artist.ellipsis
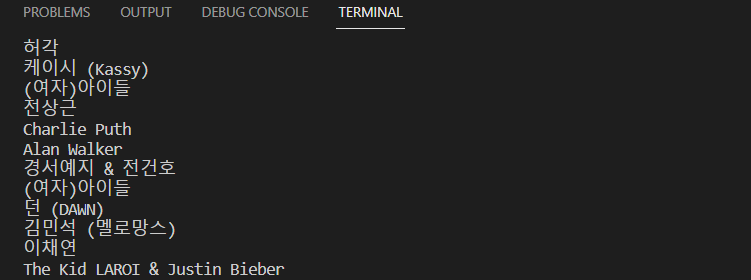
복사한 코드를 select_one( ) ← 괄호 안에 붙여넣기 한 후 쓸데 없는 tr까지의 부분은 삭제한다. 그러면 괄호 안에 들어가는 코드는 td.info > a.artist.ellipsis 이 부분이다. print(artist.text) 로 중간 점검 하면 가수 이름들이 뜨는 걸 확인할 수 있다.
.text는 artist 뒤에 붙히고 순위, 제목, 이름을 호출하는 print(rank, title, artist) 코드를 입력한다.
for tr in trs :
title = tr . select_one ( 'td.info > a.title.ellipsis' ). text . strip ()
rank = tr . select_one ( 'td.number' ). text [ 0 : 2 ]. strip ()
artist = tr . select_one ( 'td.info > a.artist.ellipsis' ). text
print ( rank , title , artist )
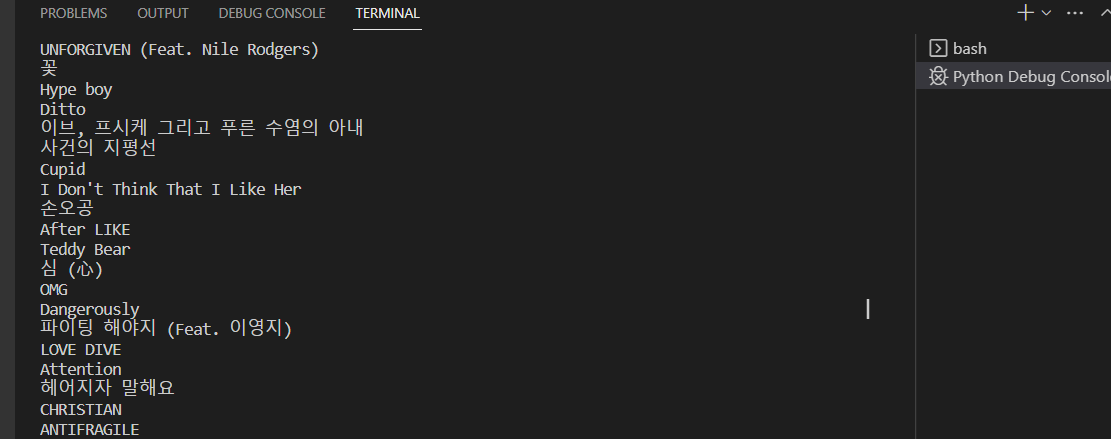
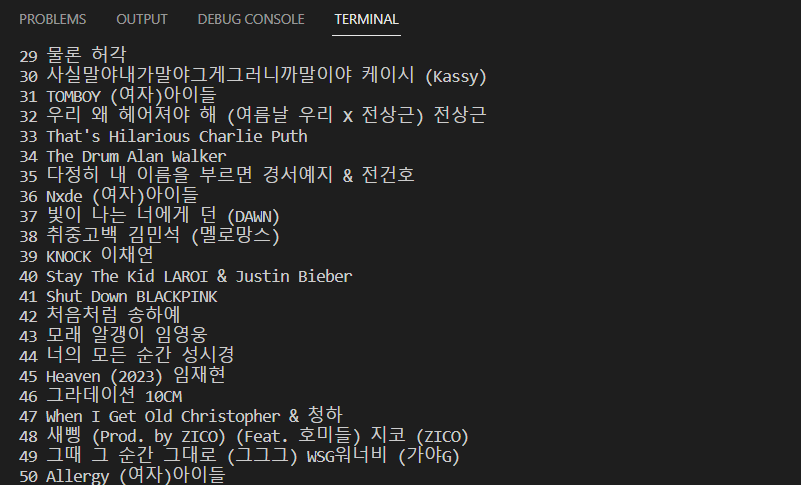
순위, 제목, 가수 이름 순으로 실행 된 결과물
아래는 완성된 전체 코드이다.
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient ( 'localhost' , 27017 )
db = client .dbsparta
# URL을 읽어서 HTML를 받아오고,
headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36' }
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
soup = BeautifulSoup ( data . text , 'html.parser' )
trs = soup . select ( '#body-content > div.newest-list > div > table > tbody > tr' )
for tr in trs :
title = tr . select_one ( 'td.info > a.title.ellipsis' ). text . strip ()
rank = tr . select_one ( 'td.number' ). text [ 0 : 2 ]. strip ()
artist = tr . select_one ( 'td.info > a.artist.ellipsis' ). text
print ( rank , title , artist )